If you are using the same data source in several Talend Open Studio subjobs, consider loading the data data into an internal data structure for use throughout a job.
A HashMap is a Java data structure maintained in RAM. Talend Open Studio lets you load manipulate data in HashMaps using the tHashInput and tHashOutput components. Because the data exists in RAM, lookups are faster, especially if secondary storage is based on spinning hard disks.
Without a HashMapThis Talend Open Studio job loads data from two spreadsheets, EmployeeHires and EmployeeTerminations, into a target table, EmployeeActions. The spreadsheet sources contain a data (hireDate and terminationDate) that is used as a key into a table called BusinessDates. Although the date could simply be carried over into the target table (without the lookup), many data warehouses maintain date information in a separate table. This is because calendar-related business information is merged with the timestamp.
This data includes flags for Holiday, Payday, and Weekday that supplement that timestamp (Month, Day, Year, Quarter) fields. The spreadsheet has been loaded into the MS SQL Server table "BusinessDates".
 |
| Basic Date Fields PLUS Business-specific Information |
A typical Talend Open Studio job will use BusinessDates as a lookup table. The main flow comes from two sources: an Employee Hires spreadsheet, and an Employee Terminations spreadsheet.
 |
| BusinessDates is Repeated for Each Subjob |
The Employee Hires spreadsheet is similar to the Terminations spreadsheets with hireDate replaced with terminationDate
.
 |
| Employee Action Source (Hires) |
Hash AlternativeThe preceding job works. 5 Hire and 3 Termination records
are written to the database. However, the job has a drawback. Even if caching is enabled, the lookup is read at least once for each subjob, leading to poorer performance. An alternative is to use the Talend Hash components: tHashInput and tHashOutput.
 |
| Job Rewritten with Talend Hash Component |
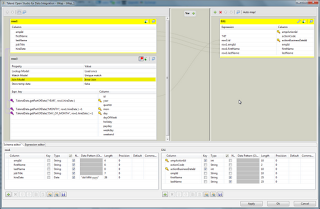
This version creates a tMap with the tHashOutput_1 component which is loaded by a database input, BusinessDates. I flag three columns as keys: year, month, day. This is for informational purposes; any fields can be used in the later tMap joins.
The tHashOutput component is configured as follows.
 |
| tHashOutput Configuration |
The schema -- with the 3 informational keys -- used in the tHashOutput follows.
The tHashOutput schema can now be applied to joins (tMap) by adding tHashInput components as lookup flows. This is the configuration of tHashInput_1 which is identical to tHashInput_2. More inputs can be added for other data loading subjobs.
 |
| tHashInput Configuration Links to tHashOutput |
In the UI, you must define a schema for both the tHashInput and tHashOutput components. I do this by setting the value to the Repository, then changing the value to Built-in and re-defining the keys from "id" to "year/month/day".
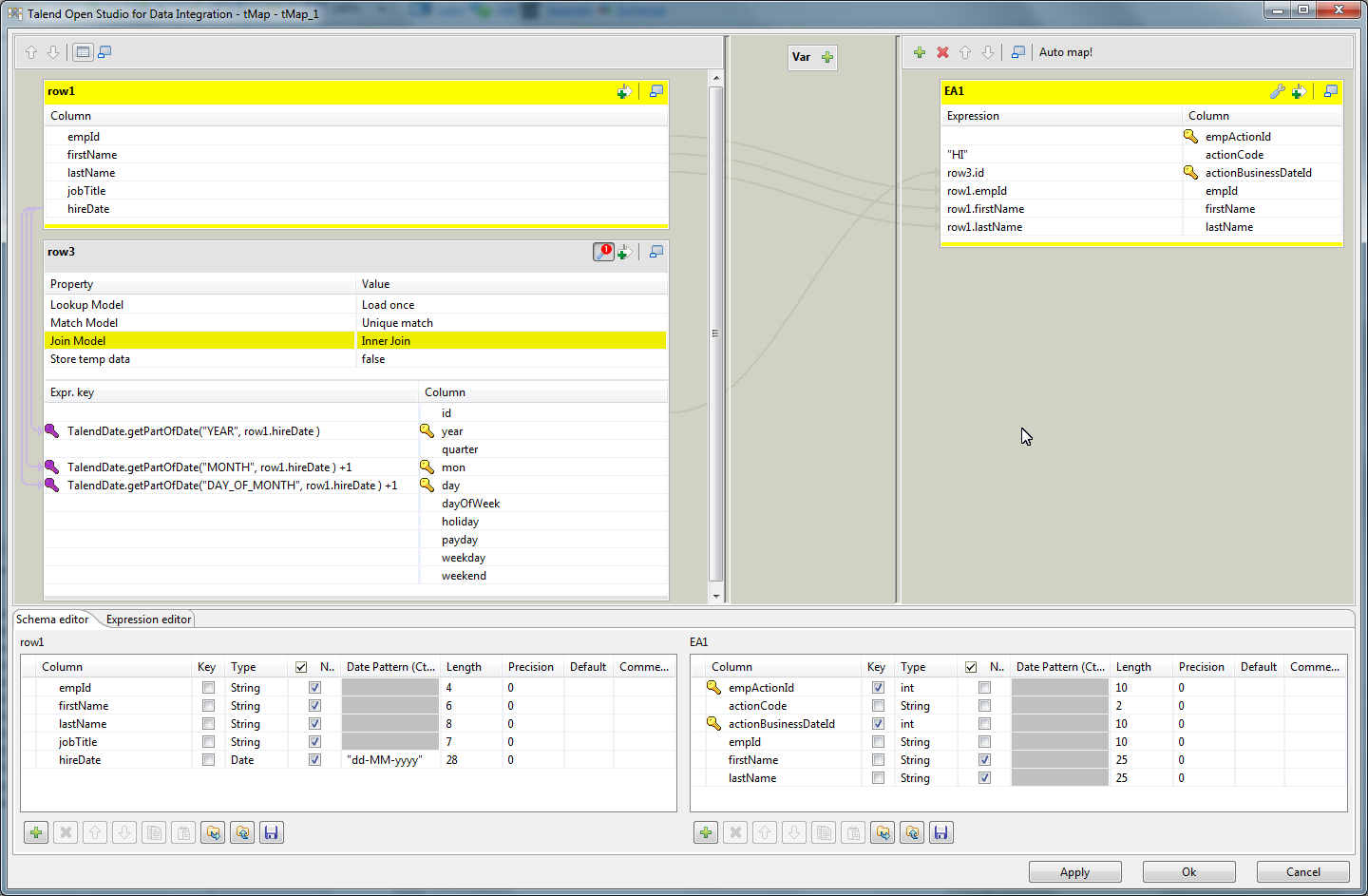
The join is performed as an Inner Join on three columns. Because the dates are represented differently, I use a TalendDate routine.
Note the important +1 which dealing with the zero-based Java month and day values.
 |
| Multi-Part Join on a Hash Map Input |
The job loads 8 records in the database. The Hires are flagged with "HI" and the Terminations with "TE".
 |
| Data Loading Results |
RAM-based data structures can provide a performance improvement since slower spinning disks aren't involved in data reads. This is a good pattern when you're dealing with data from different sources (different dbs, spreadsheets, etc). If your data processing is table-to-table in the same database, huge performance improvements can be made with the ELT* components that keep all processing within the database, eliminating the network latency of pulling the data into Talend Open Studio's JVM.









No comments:
Post a Comment