Loading a Log File with Talend Big Data
This post describes how to build a Talend Open Studio for Big Data job that loads a web server log file into a MongoDB database.
Talend Open Studio for Big Data contains Big Data components not found in the more familiar Talend Open Studio for Data Integration. TOS for Big Data has a set of components to interact with the NoSQL database MongoDB. The MongoDB components
Metadata Repository
I was surprised to find the Metadata Repository missing in the TOS Big Data download. TOS Big Data is licensed under a permissive (at least as far as object code goes) Apache license whereas Data Integration uses the reciprocal GNU license. There isn't a source code link for Big Data on Talendforge.
So, I'm using a Built-in schema for the tFileInputRegex.
The Job
The Talend job to load a log file into MongoDB looks like many others I've posted for Data Integration. A database connection supplies the host target and credentials (tMongoDBConnect). This connection is closed with a tMongoDBClose.
An input source -- tFileInputRegex -- drives a tMongoDBOutput.
The screenshot displays the canvas, input log file, and the Component View of the tFileInputRegex. The tFileInputRegex references the file displayed in the text editor (Textpad). A regular expression is constructed that will parse each line.
tFileInputRegex uses regular expression groups to map a chunk of input text into a Talend schema column. The following table breaks the expression down.
The MongoDBOutput configuration is minimal. The entries under "Mapping" are added with the schema "Sync columns" operation. The only setting I added was "things" which is a MongoDB collection I created. (A collection is like an RDBMS table, except that the definition is not restricted to a particular set of columns.)
Big Data Notes
Talend Open Studio for Big Data contains Big Data components not found in the more familiar Talend Open Studio for Data Integration. TOS for Big Data has a set of components to interact with the NoSQL database MongoDB. The MongoDB components
- tMongoDBConnection,
- tMongoDBInput,
- tMongoDBOutput, and
- tMongoDBClose
Metadata Repository
I was surprised to find the Metadata Repository missing in the TOS Big Data download. TOS Big Data is licensed under a permissive (at least as far as object code goes) Apache license whereas Data Integration uses the reciprocal GNU license. There isn't a source code link for Big Data on Talendforge.
So, I'm using a Built-in schema for the tFileInputRegex.
The Job
The Talend job to load a log file into MongoDB looks like many others I've posted for Data Integration. A database connection supplies the host target and credentials (tMongoDBConnect). This connection is closed with a tMongoDBClose.
An input source -- tFileInputRegex -- drives a tMongoDBOutput.
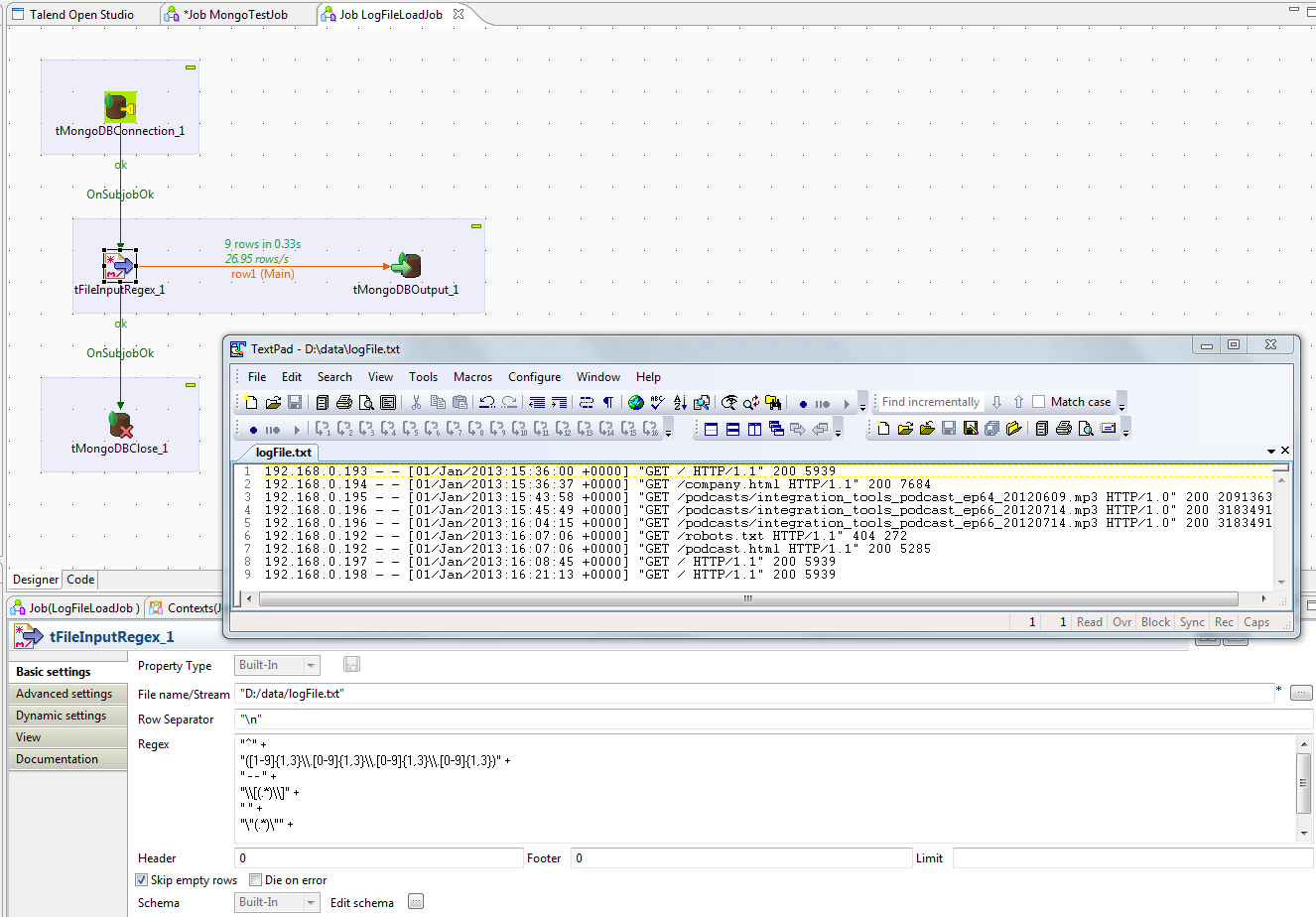 |
| A Talend Big Data Job |
tFileInputRegex uses regular expression groups to map a chunk of input text into a Talend schema column. The following table breaks the expression down.
- "^" : At the start of the string
- "([1-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3})" : Look for a group of four numbers containing one to three digits; the numbers except for the last will be separated by periods ('.')
- " - - " : The string literal " - - "
- "\\[(.*)\\]" : Everything in between [ and ]; the date part
- " " : A single space
- "\"(.*)\"" : Everything in between " and "; the request part
- ".*" : Everything else
All of the parts of interest -- the IP address, the date part, the request part -- are surrounded by the regular expression group parenthesis. These will map to columns in the following schema. Note that 'remainder' will not receive a value unless the "Everything else" is surrounded by parenthesis. The schema of the log file is synced with the tMongoDBOutput.
 |
| Schema of the Input Log File |
 |
| tMongoDBOOutput Configuration |
In RDBMS work, there is usually DDL that needs to be run to define the target table. In Talend, this can be created on-the-fly based on an "Action on table" set up in the component or a separate script run outside of Talend. For a NoSQL database like MongoDB, there is not concept of columns. Rather, by writing out the input record, all of the key / value pairs will be inserted with the object stored in MongoDB.
This means that if I change the job, say I parse the date out to its component parts -- and re-run the job, I can expect a different shape of record to be added to MongoDB. In parsing out the date, if I switch the tFileInputRegex schema to have day, month, and year rather than datePart, the newly-loaded records will differ in the properties (day versus datePart) available.
More License Notes
A dialog like this seems to be popping up a lot in Big Data. For example, dragging tMongoDBOutput displays the following dialog.
 |
| Bridging the GNU / Apache License Differences |
This was also displayed with a tMysqlOutput component.
If you're a Talend Open Studio for Data Integration developer, working with Big Data will be easier because the familiar structure of the Talend job. Jobs are configured, coded, and error-checked using the same techniques. The Metadata Repository seems like it will be missed. In order to save off your schemas, export to XML and re-import as Built-in properties of the Big Data components.
No comments:
Post a Comment